Showing
- lec/24-spark/docker-compose.yml 29 additions, 0 deletionslec/24-spark/docker-compose.yml
- lec/24-spark/nb/starter.ipynb 36 additions, 0 deletionslec/24-spark/nb/starter.ipynb
- lec/26-cassandra/Dockerfile 19 additions, 0 deletionslec/26-cassandra/Dockerfile
- lec/26-cassandra/cassandra.sh 12 additions, 0 deletionslec/26-cassandra/cassandra.sh
- lec/26-cassandra/docker-compose.yml 17 additions, 0 deletionslec/26-cassandra/docker-compose.yml
- lec/26-cassandra/src/lec1.ipynb 401 additions, 0 deletionslec/26-cassandra/src/lec1.ipynb
- lec/26-cassandra/src/lec2.ipynb 583 additions, 0 deletionslec/26-cassandra/src/lec2.ipynb
- lec/27-cassandra/hash.ipynb 261 additions, 0 deletionslec/27-cassandra/hash.ipynb
- lec/27-cassandra/lec.ipynb 1166 additions, 0 deletionslec/27-cassandra/lec.ipynb
- p2/README.md 204 additions, 0 deletionsp2/README.md
- p2/addresses.csv.gz 0 additions, 0 deletionsp2/addresses.csv.gz
- p2/arch.png 0 additions, 0 deletionsp2/arch.png
- p2/docker-compose.yml 17 additions, 0 deletionsp2/docker-compose.yml
- p3/README.md 264 additions, 0 deletionsp3/README.md
- p3/bigdata.py 27 additions, 0 deletionsp3/bigdata.py
- p3/csvsum.py 24 additions, 0 deletionsp3/csvsum.py
- p3/inputs/simple.csv 3 additions, 0 deletionsp3/inputs/simple.csv
- p3/parquetsum.py 24 additions, 0 deletionsp3/parquetsum.py
- p3/upload.py 23 additions, 0 deletionsp3/upload.py
- p4/.gitignore 3 additions, 0 deletionsp4/.gitignore
lec/24-spark/docker-compose.yml
0 → 100644
lec/24-spark/nb/starter.ipynb
0 → 100644
lec/26-cassandra/Dockerfile
0 → 100644
lec/26-cassandra/cassandra.sh
0 → 100644
lec/26-cassandra/docker-compose.yml
0 → 100644
lec/26-cassandra/src/lec1.ipynb
0 → 100644
This diff is collapsed.
lec/26-cassandra/src/lec2.ipynb
0 → 100644
This diff is collapsed.
lec/27-cassandra/hash.ipynb
0 → 100644
This diff is collapsed.
lec/27-cassandra/lec.ipynb
0 → 100644
This diff is collapsed.
p2/README.md
0 → 100644
This diff is collapsed.
p2/addresses.csv.gz
0 → 100644
File added
p2/arch.png
0 → 100644
{kind=link}
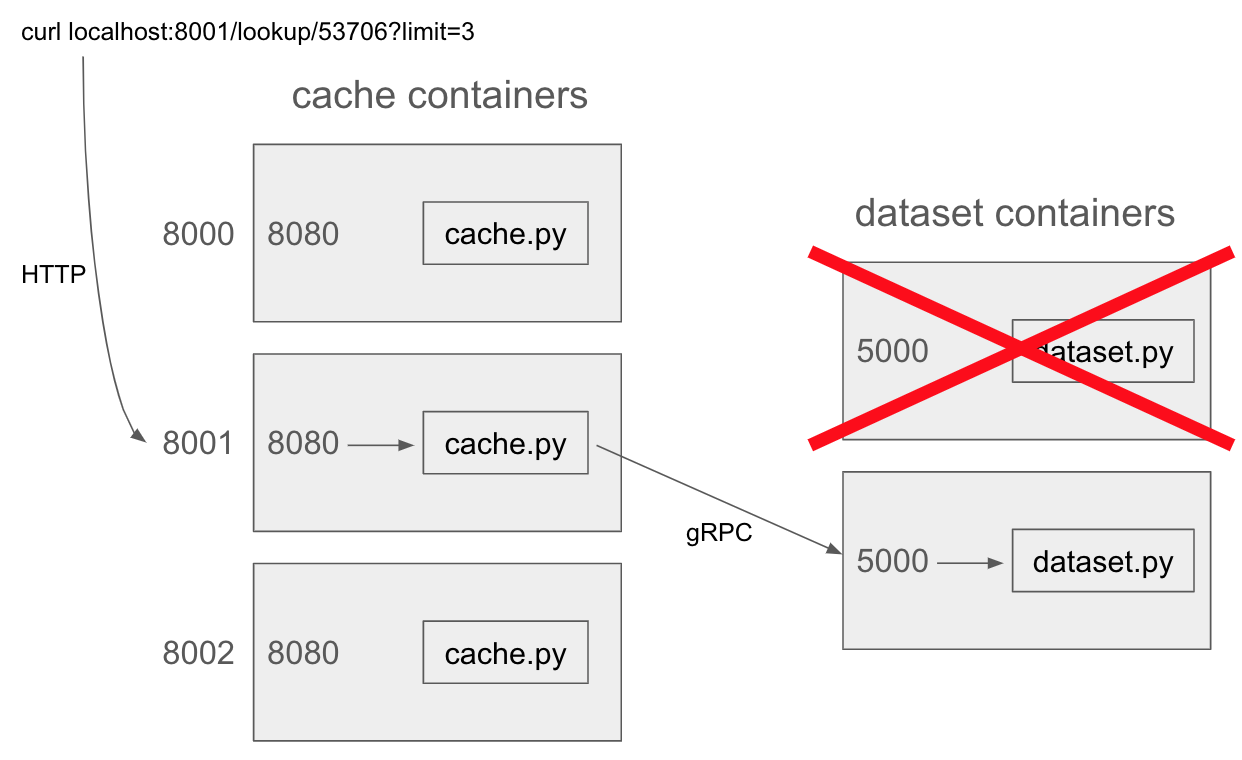
101 KiB
p2/docker-compose.yml
0 → 100644
p3/README.md
0 → 100644
This diff is collapsed.
p3/bigdata.py
0 → 100644
p3/csvsum.py
0 → 100644
p3/inputs/simple.csv
0 → 100644
p3/parquetsum.py
0 → 100644
p3/upload.py
0 → 100644
p4/.gitignore
0 → 100644