{kind=link}
DRAFT! Don't start yet.
P4 (4% of grade): SQL and HDFS
Overview
In this project, you will depoly a data system consisting of an SQL server, an HDFS cluster, a gRPC server, and a client. You will need to read and filter data from a SQL database and persist it to HDFS. Then, you will partition the data to enable efficient request processing. Additionally, you will need to write a fault-tolerant application that works even when an HDFS DataNode fails (we will test this scenario).
Learning objectives:
- communicate with the SQL Server using SQL queries
- use the WebHDFS API
- utilize PyArrow to interact with HDFS and process Parquet files
- handle data loss scenario
Before starting, please review the general project directions.
Corrections/Clarifications
- none yet
Introduction
You'll need to deploy a system including 5 docker containers like this:
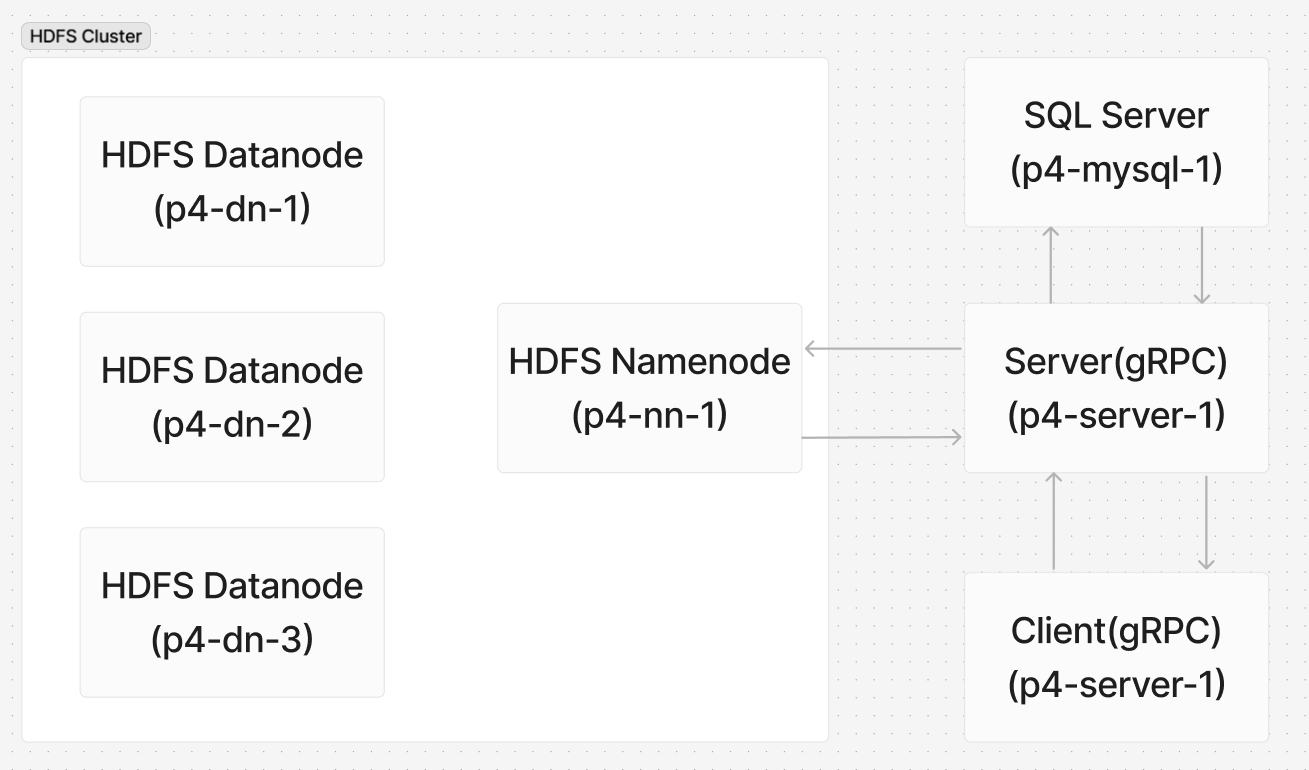
We have provided the other components; what you only need is to complete the work within the gRPC server and its Dockerfile.
Client
This project will use docker exec -it to run the client on the gRPC server's container. Usage of client.py is as follows:
#Inside the server container
python3 client.py DbToHdfs
python3 client.py BlockLocations -f <file_path>
python3 client.py PartitionByCounty
python3 client.py CalcAvgLoan -c <county_code>Docker Compose
Take a look at the provided Docker compose file. There are several services, including datanodes with 3 replicas, a namenode, a SQL server, a gRPC Server. The NameNode service will serve at the host of boss within the docker compose network.
gRPC
You are required to write a server.py and Dockerfile.server based on the provided proto file (you may not modify it).
The gRPC interfaces have already been defined (see lender.proto for details). There are no constraints on the return values of DbToHdfs and PartitionByCounty, so you may return what you think is helpful.
Docker image naming
You need to build the Docker image following this naming convention.
docker build . -f Dockerfile.hdfs -t p4-hdfs
docker build . -f Dockerfile.namenode -t p4-nn
docker build . -f Dockerfile.datanode -t p4-dn
docker build . -f Dockerfile.mysql -t p4-mysql
docker build . -f Dockerfile.server -t p4-serverPROJECT environment variable
Note that the compose file assumes there is a "PROJECT" environment variable. You can set it to p4 in your environment:
export PROJECT=p4Hint 1: The command docker logs <container-name> -f might be very useful for troubleshooting. It allows you to view real-time output from a specific container.
Hint 2: Think about whether there is any .sh script that will help you quickly test code changes. For example, you may want it to rebuild your Dockerfiles, cleanup an old Compose cluster, and deploy a new cluster.
Hint 3: If you're low on disk space, consider running docker system prune -a --volumes -f
Part 1: Load data from SQL Database to HDFS
In this part, your task is to implement the DbToHdfs gRPC call (you can find the interface definition in the proto file).
DbToHdfs: To be more specific, you need to:
- Connect to the SQL server, with the database name as
CS544and the password asabc. There are two tables in databse:loans,andloan_types. The former records all information related to loans, while the latter maps the numbers in the loan_type column of the loans table to their corresponding loan types. There should be 447367 rows in tableloans. It's like:mysql> show tables; +-----------------+ | Tables_in_CS544 | +-----------------+ | loan_types | | loans | +-----------------+ mysql> select count(*) from new_table; +----------+ | count(*) | +----------+ | 426716 | +----------+ - What are the actual types for those loans?
Perform an inner join on these two tables so that a new column
loan_type_nameadded to theloanstable, where its value is the correspondingloan_type_namefrom theloan_typestable based on the matchingloan_type_idinloans. - Filter all rows where
loan_amountis greater than 30,000 and less than 800,000. After filtering, this table should have only 426716 rows. - Upload the generated table to
/hdma-wi-2021.parquetin the HDFS, with 3x replication, using PyArrow.
To check whether the upload was correct, you can use docker exec -it to enter the gRPC server's container and use HDFS command hdfs dfs -du -h <path>to see the file size. The expected result is:
14.4 M 43.2 M hdfs://boss:9000/hdma-wi-2021.parquet Hint 1: We used similar tables in lecture: https://git.doit.wisc.edu/cdis/cs/courses/cs544/s25/main/-/tree/main/lec/15-sql
Hint 2: To get more familiar with these tables, you can use SQL queries to print the table schema or retrieve sample data. A convenient way to do this is to use docker exec -it to enter the SQL Server, then run mysql client mysql -p CS544 to access the SQL Server and then perform queries.
Hint 3: After docker compose up, the SQL Server needs some time to load the data before it is ready. Therefore, you need to wait for a while, or preferably, add a retry mechanism for the SQL connection.
Hint 4: For PyArrow to be able to connect to HDFS, you'll need to configure some env variables carefully. Look at how Dockerfile.namenode does this for the start CMD, and do the same in your own Dockerfile for your server.
Part 2: BlockLocations
In this part, your task is to implement the BlockLocations gRPC call (you can find the interface definition in the proto file).
BlockLocations: To be more specific, for a given file path, you need to return a python directory(i.e. map in proto), recording how many blocks there are in each data node(key is the datanode location and value is number of blocks on that node).
The return value of gRPC call BlockLocations should be something like:
{'dd8706a32f34': 6, '21a88993bb15': 4, '47c17821001f': 5}Note: datanode loacation is the randomly generated container ID for the container running the DataNode, so yours will be different, and the distribution of blocks across different nodes may also vary.
The documents here describe how we can interact with HDFS via web requests. Many examples show these web requests being made with the curl command, but you'll adapt those examples to use requests.get. By default, WebHDFS runs on port 9870. So use port 9870 instead of 9000 to access HDFS for this part.
Hint1: Note that if r is a response object, then r.content will contain some bytes, which you could convert to a dictionary; alternatively,r.json() does this for you.
For example:
r = requests.get("http://boss:9870/webhdfs/v1/<filepath>?op=GETFILESTATUS")
r.raise_for_status()
print(r.json())You might get a result like:
{'FileStatus': {...
'blockSize': 1048576,
...
'length': 16642976,
...
'replication': 1,
'storagePolicy': 0,
'type': 'FILE'}}Hint2: You can use operation GETFILESTATUS to get file lenth and blocksize, and use the openoperation with appropriate offset to retrieve the node where each block is located.
Part 3: Calculate the average loan for each county
In this part, your task is to implement the PartitionByCounty and CalcAvgLoan gRPC calls (you can find the interface definition in the proto file).
Imagine a scenario where there could be many queries differentiated by county, and one of them is to get the average loan amount for a county. In this case, it might be much more efficient to generate a set of 1x Parquet files filtered by county, and then read data from these partitioned, relatively much smaller tables for computation.
PartitionByCounty: To be more specific, you need to categorize the contents of that parquet file just stored in HDFS using county_id as the key. For each county_id, create a new parquet file that records all entries under that county, and then save them with a 1x replication. Files should be written into folder /partitioned/ and name for each should be their county_id.
CalcAvgLoan: To be more specific, for a given county_id , you need to return a int value, indicating the average loan_amount of that county. Note: You are required to perform this calculation based on the partitioned parquet files generated by FilterByCounty. source field in proto file can ignored in this part.
The inside of the partitioned directory should look like this:
```
├── partitioned/
│ ├── 55001.parquet
│ ├── 55003.parquet
│ └── ...
```The root directory on HDFS should now look like this:
14.4 M 43.2 M hdfs://boss:9000/hdma-wi-2021.parquet
19.3 M 19.3 M hdfs://boss:9000/partitionedPart 4: Fault Tolerant
In this part, your task is to modify the CalcAvgLoan gRPC calls you implemented in Part3.
Imagine a scenario where one (or even two) of the three DataNodes fail and go offline. In this case, can the logic implemented in Part 3 still function correctly? If we still want our gRPC server to correctly respond to requests for calculating the average loan, what should we do?
Keep in mind that /hdma-wi-2021.parquet has a replication factor of 3, while /partitioned only has a replication factor of 1.
CalcAvgLoan: To be more specific, modify this gRPC call to support the server in correctly handling responses even when one (or even two) DataNode is offline. You may try reading the partitioned parquet file first. If unsuccessful, then go back to the large hdma-wi-2021.parquet file and complete the computation. What's more, you have to return with the field source filled:
- "partitioned": calculation performed on parquet partitioned before
- "unpartitioned": parquet partitioned before is lost, and calculation performed on the initial unpartitioned table
To simulate a data node failure, you should use docker kill to terminate a node and then wait until you confirm that the number of live DataNodes has decreased using the hdfs dfsadmin -fs <hdfs_path> -report command.
Submission
Read the directions here about how to create the repo.
You have some flexibility about how you write your code, but we must be able to run it like this:
docker build . -f Dockerfile.hdfs -t p4-hdfs
docker build . -f Dockerfile.namenode -t p4-nn
docker build . -f Dockerfile.datanode -t p4-dn
docker build . -f Dockerfile.mysql -t p4-mysql
docker build . -f Dockerfile.server -t p4-server
docker compose up -dWe will copy in the all the dockerfiles except "Dockerfile.server", "docker-compose.yml", "client.py", "lender.proto", and "hdma-wi-2021.sql.gz", overwriting anything you might have changed.
Please make sure you have client.py copied into p4-server-1. We will run client.py in p4-server-1 to test your code.
Tester
Not released yet.